
Revenue agents operate in one of the messiest data environments imaginable. A seller's world spans CRM records, email threads, meeting transcripts, call recordings, LinkedIn profiles, company news, and dozens of other signals, all constantly changing.
A deal that looked dead last week has a new champion today. A contact who was irrelevant yesterday just got promoted to VP. Unlike a codebase that sits still while you work on it, the ground truth shifts daily.
The challenge compounds when you consider how agents actually work.
Most of the context fed into an agentic system is determined at runtime, based on the outputs of previous LLM calls. Depending on user intent and how the agent explores, different data gets fetched, fundamentally altering downstream execution. Ask the same question twice and you might get different tool calls, different context, different answers. This isn't because anything is broken, but because the agent is responding to a world that moved.
This is why evals matter. LLMs are non-deterministic. Agents layer decision-making on top of decision-making. Without rigorous evaluation, you're flying blind, shipping changes and hoping nothing broke. But building good evals is its own challenge: you need to capture the full state of a seller's world at a point in time and replay agent execution against that frozen snapshot, realistic enough to exercise real behavior but bounded enough to be reproducible.
Our approach: The Knowledge Graph and controlled query interface
A core thesis of Rox is unifying all data sources into the Rox Knowledge Graph. Instead of agents hitting scattered integrations at runtime, there's a single entry point to access everything. Contacts, companies, opportunities, meetings, and emails are all represented as nodes and edges in one graph. Entity resolution and ingestion happen ahead of time, so agents work with clean, unified data rather than stitching together raw API responses on the fly.
We go a step further: agents don't run arbitrary queries against the Knowledge Graph. Instead, we expose a set of predefined queries, each with semantic meaning described in natural language. This handholds the agent. Rather than figuring out how to traverse a graph, it picks from queries like "get recent meetings with this contact" or "find open opportunities at this company." It also enforces security: an agent can never access data it shouldn't see because we control exactly which queries exist.
These predefined queries make up the AgentDataInterface, the agent's controlled access layer to all customer data. Every agent at Rox, regardless of what it does, talks to the same interface. This is what makes building turn-key agents possible, and it's what makes our eval strategy work.
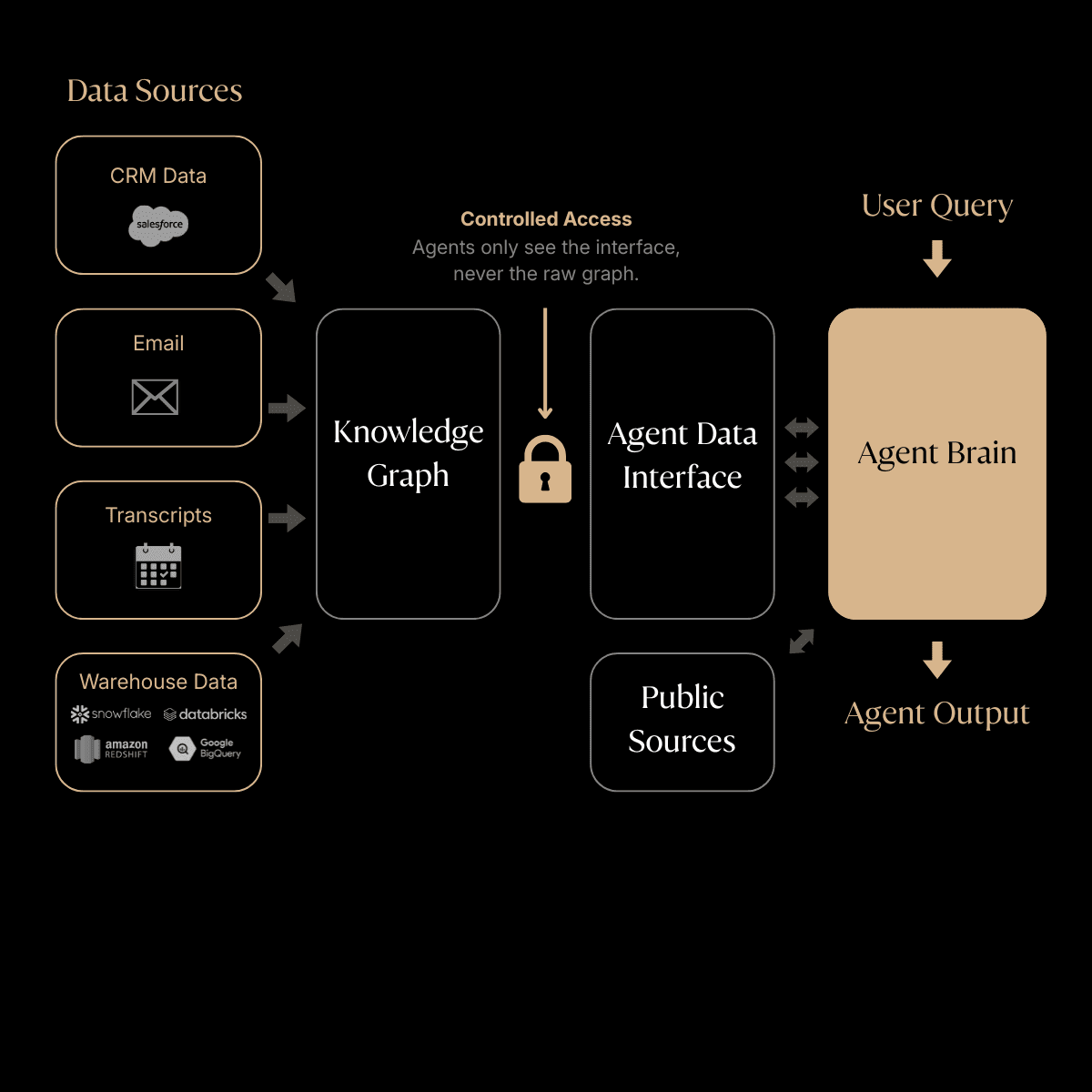
The AgentDataInterface: how it works
The AgentDataInterface is a controlled set of queries that define everything an agent can access. Each query has a name, a natural language description for the LLM, and a parameterized implementation under the hood.
Here's a concrete example.
One query might be:
get_recent_emails_with_contact
"Retrieve the most recent emails between the current user and a specific contact."
The agent sees the name and description. When it decides to call this query, it provides the parameters it controls: which contact rox_person_id) and how many emails limit). But the implementation enforces parameters the agent never touches:
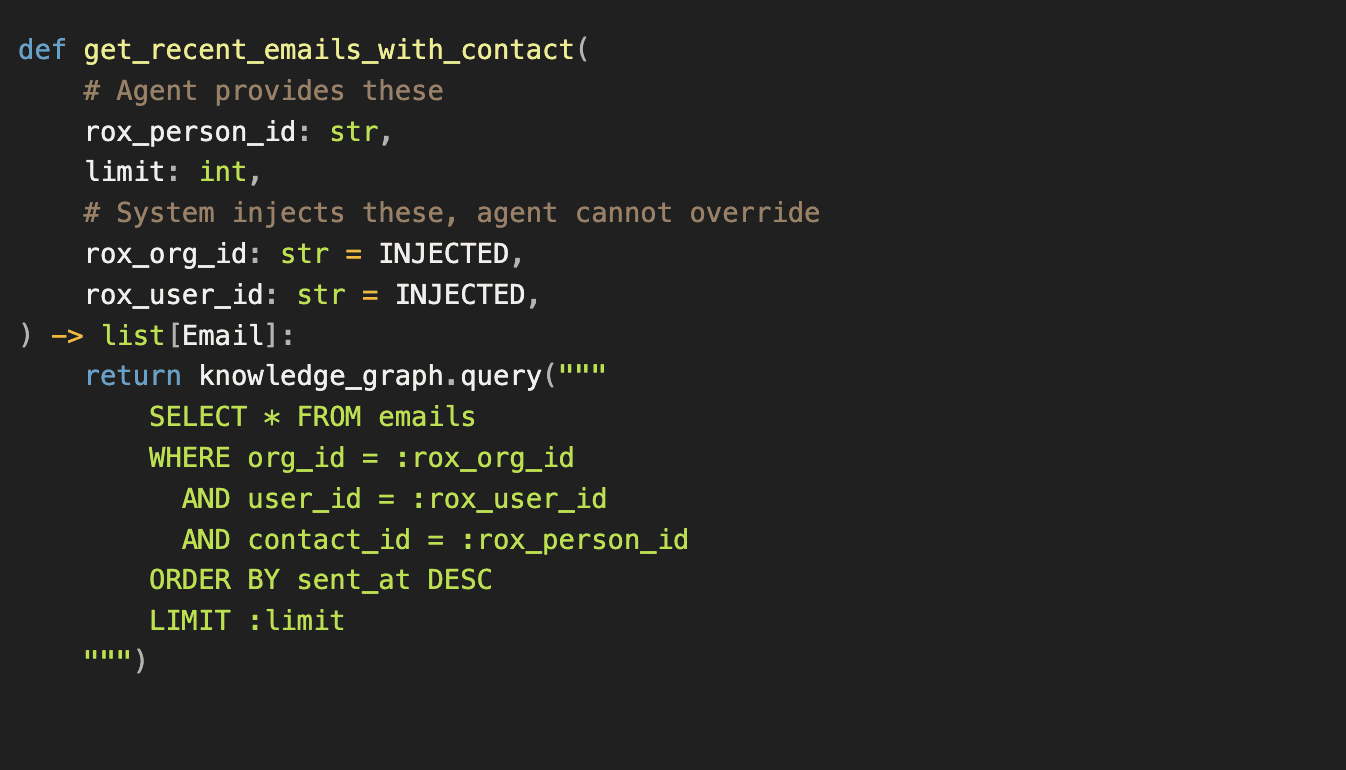
The agent picks the contact and the count. The system forces the org and user scoping. There's no way for the agent to query across orgs or access another user's emails because those parameters aren't exposed.
Every query in the AgentDataInterface follows this pattern. The agent gets flexibility where it needs it, and hard boundaries everywhere else. This is how we build agents that are both capable and safe by construction.
Snapshotting for evals: creating repeatable environments
The AgentDataInterface is defined as an abstract base class. Every method must be implemented by both LiveDataInterface and MockDataInterface. When you add a new query, you're forced to implement both. Developers get mocks for free as a side effect of building the live implementation. `
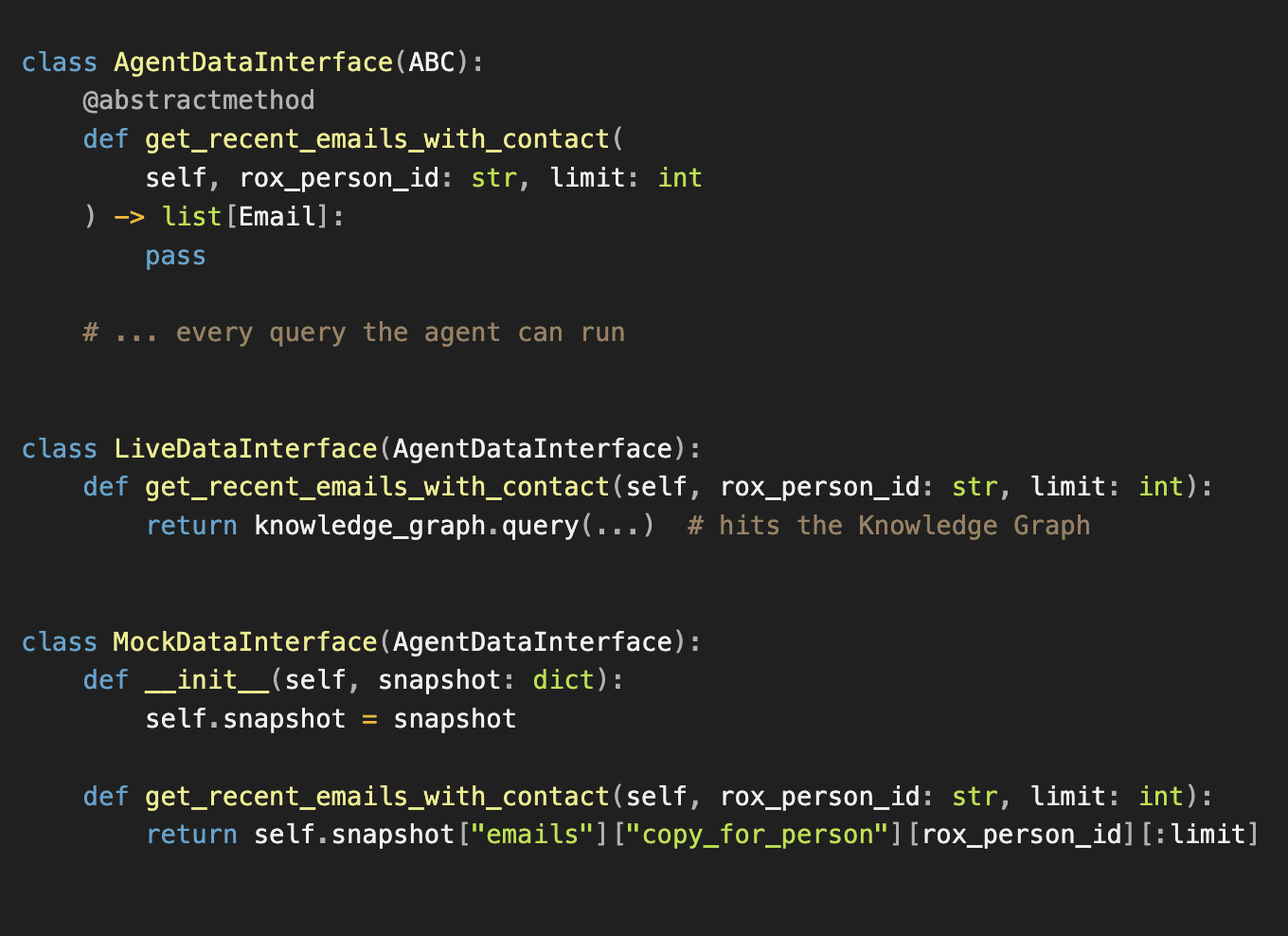
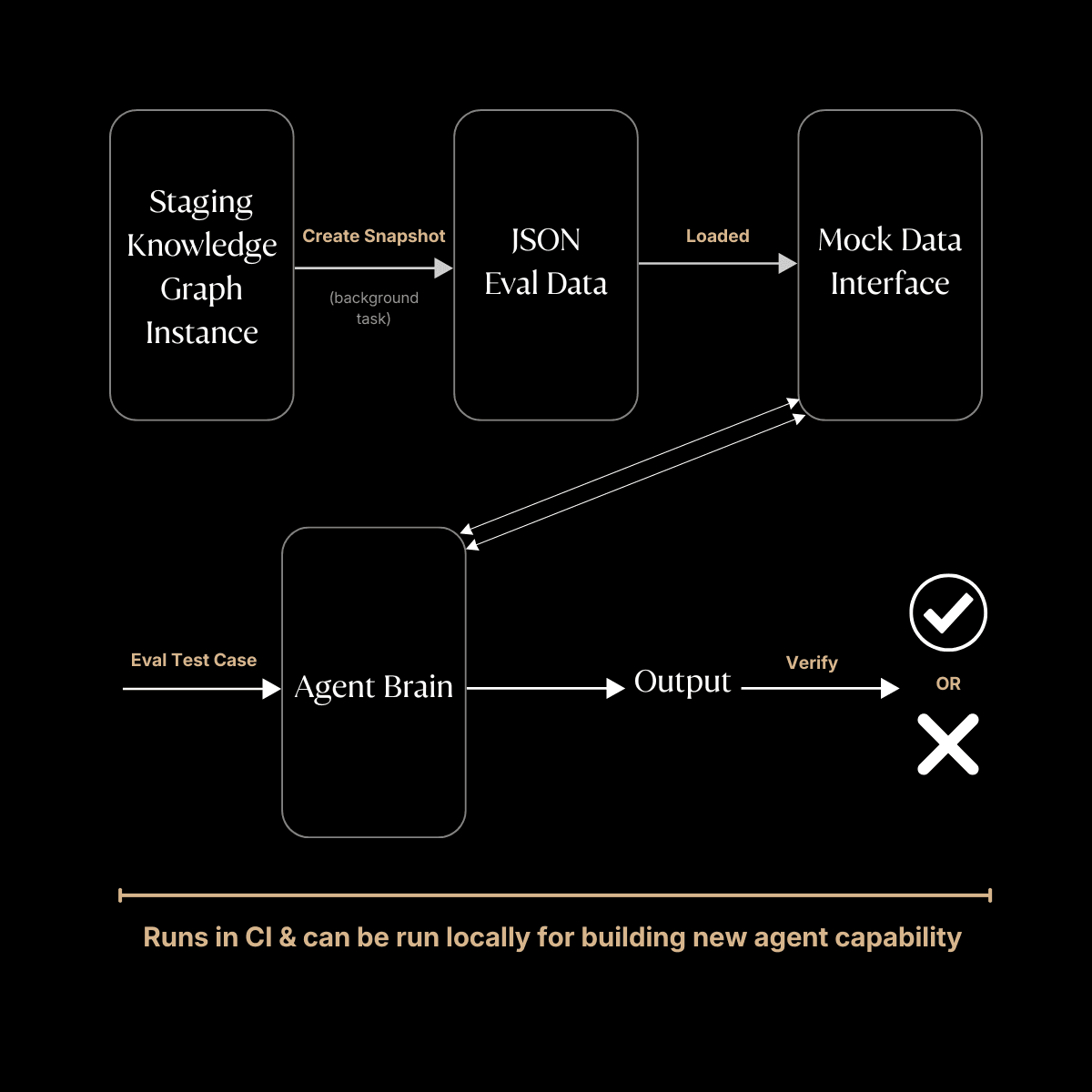
For evals, we snapshot real environments by running aggregator knowledge graph queries against staging data. Background tasks execute these queries and write the results to a single JSON file representing the full state of a seller's CRM at that point in time: their contacts, companies, opportunities, recent emails, meetings, transcripts. One file captures everything an agent could ask for.
The eval runner loads this JSON and swaps LiveDataInterface for MockDataInterface. From the agent's perspective, nothing changes. It calls the same methods with the same signatures. But instead of hitting the Knowledge Graph, it reads from the snapshot.
This unlocks two workflows. First, we run evals in CI on every commit. The agent executes against frozen snapshots and we compare outputs to catch regressions before they ship. Second, developers can run evals locally. Change a prompt, swap a model, refactor orchestration logic, and immediately see if performance improved or degraded. No waiting for deployment, no relying on staging data that might have shifted.
The abstract base class is the key. It guarantees that any query available in production has a mock equivalent, and that snapshots stay in sync with the interface as it evolves.
What we measure: eval criteria and scoring
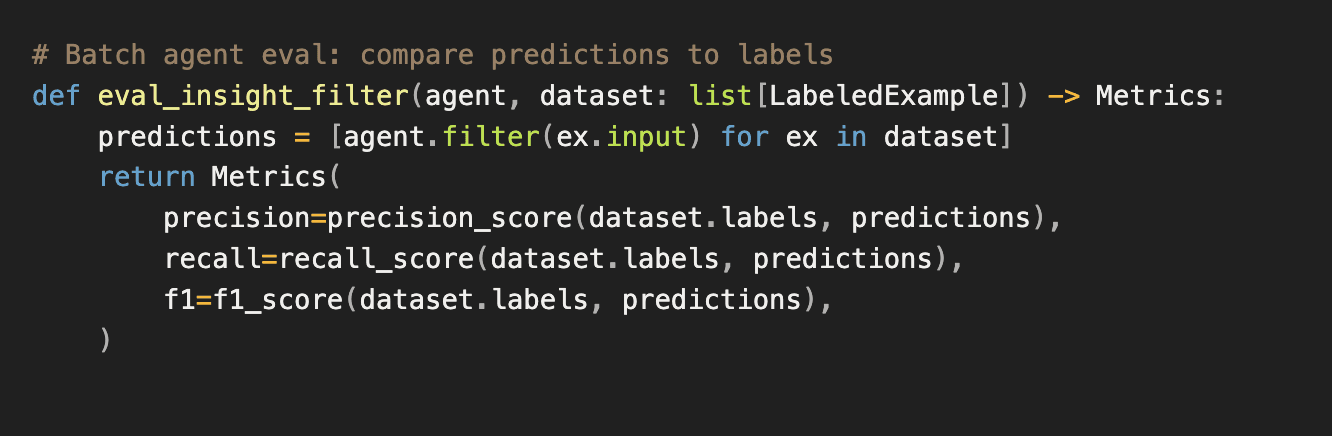
Evaluation criteria depend on the complexity of the agent. For simpler batch agents like insight filtering or next best action ranking, we maintain human labeled datasets. These agents take a fixed input and produce a discrete output, so we can directly compare predictions against ground truth labels. Standard classification metrics apply.
For deeper agentic systems, the challenge shifts. The agent makes multiple decisions across many LLM calls, retrieves context dynamically, and synthesizes a response. Evaluating final output quality is useful but doesn't tell you where things went wrong. The more actionable question is: did the agent retrieve the right context for the given query?
One way we test this is with needle in haystack. For a given eval case, we insert a known piece of information into the snapshot, something the agent must retrieve to answer correctly. A specific detail buried in meeting transcripts, a fact hidden in an email thread, a data point in an opportunity record. Then we assert that the agent's response surfaces it.
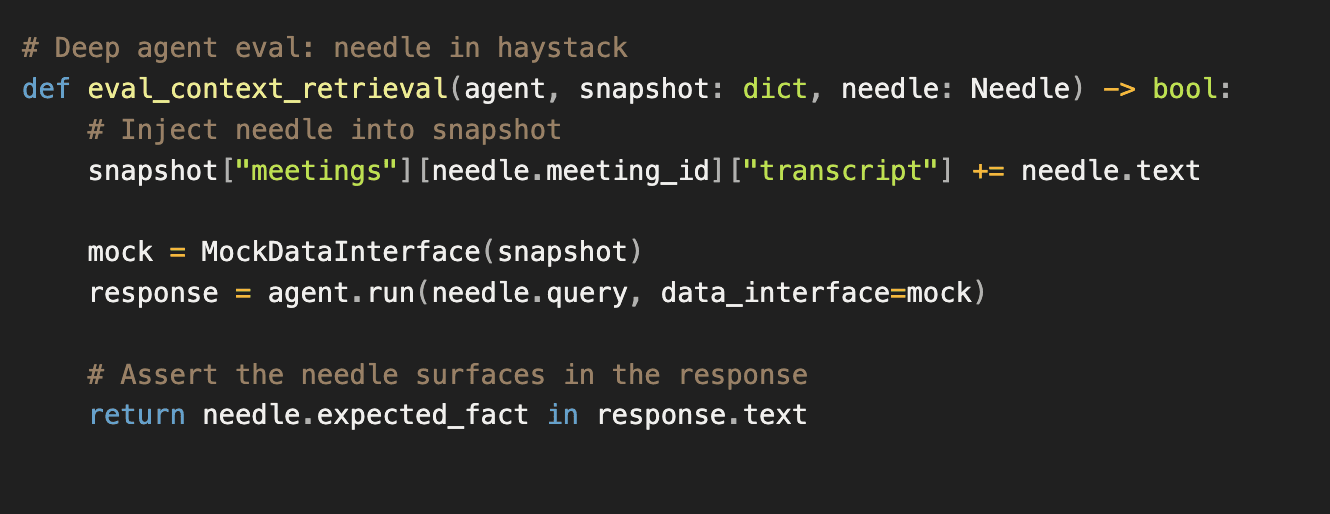
This approach tests the full retrieval pipeline: whether the agent picked the right queries, passed the right parameters, and pulled the relevant context from the results. If the needle doesn't appear in the response, something in that chain broke. We can trace back through the execution to find where.
Why this matters
Enterprise customers don't tolerate flaky agents. They need consistent, reliable behavior across thousands of users with complex data environments. The only way to deliver that is through rigorous evaluation, but you can't evaluate what you can't reproduce. By unifying data access through the Knowledge Graph, constraining agent behavior with the AgentDataInterface, and snapshotting environments for deterministic replay, we've built an eval framework that lets us ship with confidence. Regressions get caught in CI. Prompt changes get validated locally before they hit production. New capabilities get tested against real world data shapes. This infrastructure isn't glamorous, but it's what separates demo-quality agents from production-grade systems.


